Our reach
Our books are available in all of the usual sales channels, but because they are open access, they are also available via many open platforms. We are able to collect information from some of these platforms about how often our books are downloaded or accessed.
We collect and display detailed readership statistics (also known as usage data, or metrics) for our books on each book's home page. There you can see how often the book has been downloaded or read online via a number of different platforms, including our own website and external platforms such as the OAPEN Library and Google Books. There are also some geographical data about where the book has been accessed. See further down this page for more information about how we collect this data, and how we aggregate it for each book.
The data we collect is not comprehensive, because each book can be shared easily in multiple ways we cannot track. That's the nature -- and the benefit -- of open access! This means that our figures will be less than the actual usage of the book. But this information can can give us an indication of the extent to which our books are being downloaded and accessed, and where.
Presented below are our global geographical statistics for the year 2025, showcasing the breadth of some of the geographical engagement with our titles.
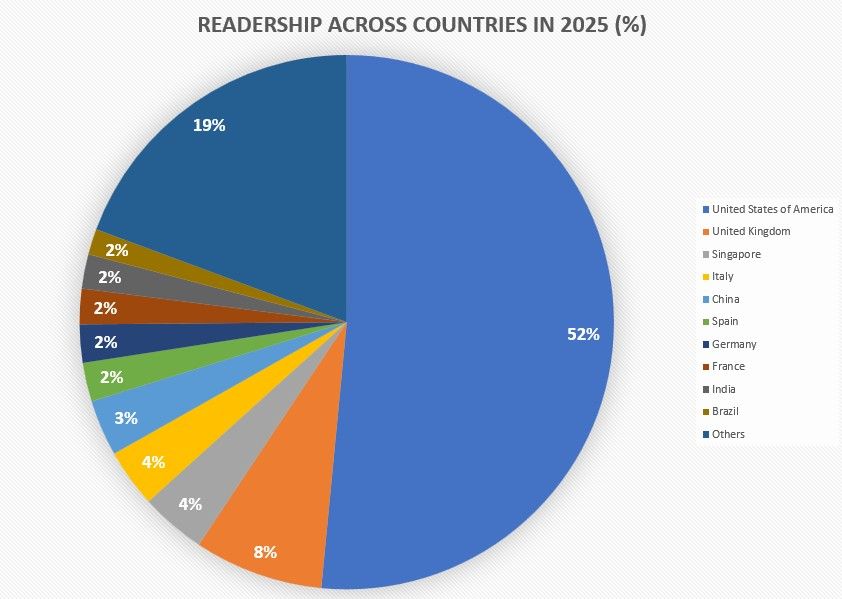
In the global landscape of our readership, discernible patterns emerge across countries. The United States of America leads with a substantial readership, followed by the United Kingdom, Singapore, Italy, and China. Noteworthy engagement can also be seen in Spain, Germany, France, India, and Brazil.
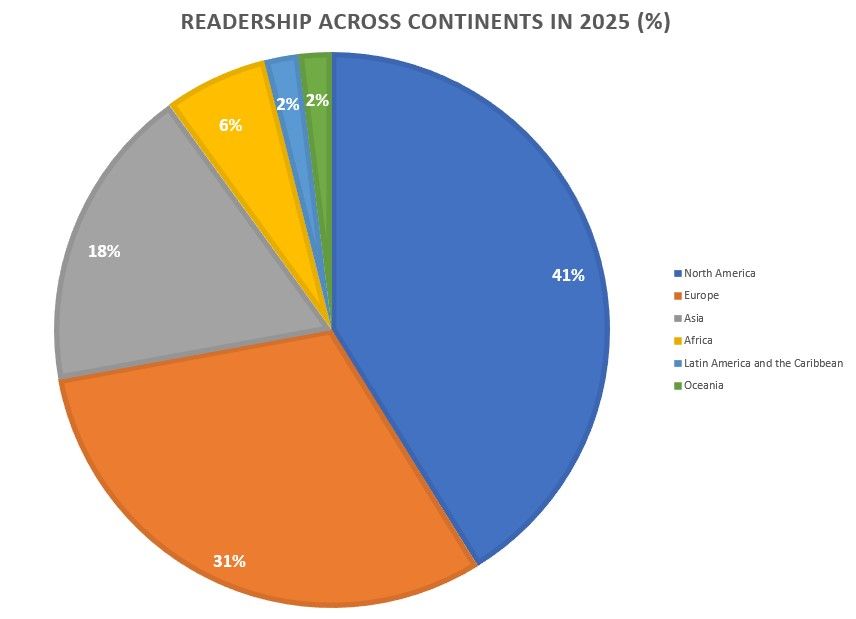
This demonstrates the widespread usage of our books on a global scale. Pulling back further, below you can find a chart of readership by continent in 2025:
For more information about how we collect usage data about our books, keep reading!
Readership Statistics
How We Collect our Readership Statistics
You might have noticed that we provide readership data for each of our books online, including the number of times each book has been viewed and the location of the readers. If you would like to know more about how this data is collected and where it comes from, read on!
Our readership data is composed of different measures obtained from different platforms:
| Platform | Measure | Geographic information | Update frequency |
|---|---|---|---|
| OBP Downloads | Book downloads | Yes* | Daily |
| OBP HTML Reader | Book sessions | Yes | |
| Google Books | Book visits | No | Daily |
| OBP PDF Reader | Book sessions | Yes | |
| Classics Library | Book sessions | Yes | Daily |
| OAPEN | Book downloads | Yes | Monthly |
| Open Edition | Book visits | No | Monthly |
| Open Edition | Book downloads | No | Monthly |
| World Reader | Book users | Yes | |
| Unglue.it | Book downloads | No | Quarterly |
| Internet Archive | Book visits | No | Quarterly |
| Kindle | Book downloads | No | Quarterly |
* OBP Downloads include geographic information from November 2021 onwards.
** Access to our books in HTML format was tracked until July 2023. Unfortunately, the platform we relied on to record this information is no longer available. Our developers at OBP are actively exploring solutions to address this issue and resume the collection of this data.
*** OBP PDF reader was not implemented for books published from July 2021 onwards, and was finally deprecated for all books in September 2021.
**** World Reader has not provided us with usage stats since early 2020. Since March 2023, World Reader is no longer hosting academic books.
A Book Session is a group of visits made by the same user within a continuous time frame. To record these sessions we use Google Analytics, and a session lasts until there are 30 minutes of inactivity; if a single user keeps interacting with the website within this time frame, multiple visits to the same book will be counted as one session. For more information on Google Analytics’ definition of a session read: How a web session is defined in Analytics.
It is important to note that we use Google Analytics’ measure for a Book Session rather than an alternative such as COUNTER, because Google Analytics has a stricter measure for the length of a Book Session. COUNTER has a much shorter time frame for a single Session, and therefore records more Sessions than Google Analytics. We do collect data for our books that would meet COUNTER's measures, but we don’t record it publicly. For more information about COUNTER see: https://www.projectcounter.org/
Find more information on how Google Books records traffic.
Book Visits represent the total number of times a book has been accessed. This can include multiple visits by the same IP address, which are counted as separate visits.
Book Downloads represent the total number of times a book has been downloaded. In addition to the download data we receive from Unglue.it, we collect free ebook download data from other platforms including our own website, Kindle, Google Play, etc, and we add these into the statistics we report. However, these download figures are calculated slightly differently on each platform, depending on whether repeat downloads to the same IP address in quick succession are counted as two downloads or one. As with Book Sessions, we err on the side of the lower figure wherever possible.
Geographic information: most platforms do not provide geographic information about the users accessing their content, and some people configure their browsers to block any third party tracking scripts attempting to collect such information (e.g., Google Analytics). For these reasons we are only able to provide readership data by country for a small percentage of our total figures - about 40%.
We try to provide as complete a picture as possible about the number of times our books have been freely accessed, as well as the location of the readers, because this information helps to demonstrate the value of Open Access publishing.
Further reading
- More about what we can learn from our readership data--and what we can't.
- For details of the open source software we have developed to obtain accurate readership metrics, see OA Book Usage Data.
Metrics API
You may query all our usage stats via our REST API: https://metrics.api.openbookpublishers.com/
The open source software that powers the API was developed by OBP for the HIRMEOS project. The OPERAS consortium runs its own metrics API, to which we also contribute all our stats, at https://metrics-api.operas-eu.org.
API routes
We allow the following methos on the API:
| Method | Route | Description |
|---|---|---|
GET | /measures | List the descriptions of the measures available in the API |
GET | /events | Retrieves the measures from the API with various parameters, see below |
GET /events parameters
When retrieving measures, you can (and should) provide some parameters to the request, they can be seen below:
| Parameter | Description |
|---|---|
| aggregation | The results can be aggregated on certain values, i.e. aggregation on measure_uri. Aggregation must be one of the following: empty, measure_uri,country_uri, year,measure_uri, measure_uri,month, month,measure_uri, measure_uri,year, country_uri,measure_uri, measure_uri. |
| filter | Many different options can be used in the filter, i.e. filtering on measure_uri or on work_uri. Those can be together or even used multiple times by separating them with a comma "," |
Examples
- Example of simple query on a DOI and results aggregated by the measure_uri:
https://metrics.api.openbookpublishers.com/events?aggregation=measure_uri&filter=work_uri:info:doi:10.11647/obp.0020 - Example of the same query but selecting only a couple of measures:
https://metrics.api.openbookpublishers.com/events?aggregation=measure_uri&filter=work_uri:info:doi:10.11647/obp.0020,measure_uri:https://metrics.operas-eu.org/oapen/downloads/v1,measure_uri:https://metrics.operas-eu.org/obp/downloads/v1